NO EXECUTE!
(c) 2015 by Darek Mihocka, founder, Emulators.com.
May 6 2015
Why static compiler optimizations are not enough
I've discussed how modern Haswell and Broadwell micro-architectures have made great advances in the efficiency of x86 and raising per-core IPC rates to more than triple where they were a decade ago. Now let's look at some simple C code to demonstrate how modern compilers still fail to take full advantage of this.
After a developer has authored some source code, there are two opportunities to optimize the generate machine code - at compile time when creating the executable that goes on disk, and at run time when loading and running that executable in memory. The first is of course called "static optimization" and the latter is called "dynamic optimization". High level languages like Java and C# use both types of optimization by design - statically compiling to Java or MSIL bytecode, and then dynamically jitting that bytecode to native machine code at run time.
For today let's focus on native machine codes like x86 or ARM, where generally the focus with those has been only on the static optimization at compile time with no further optimization at run time. Even in a perfectly monolithic world - let's imagine a world of the recent past where most desktops, laptops, and servers were Intel x86 based - there is a need for dynamic optimization. As I've discussed from my own experience, even when you hand code in x86 assembly and cycle-count the hell out of your code to make it as optimal as possible (as I did in 1999 when tuning SoftMac for the Intel Pentium III) a new processor will come along the next year (e.g. the Pentium 4 in 2000) and completely break all the optimizations. Exactly what happened to me, where I found my beautifully tuned hand code suddenly lost half of its performance running on Pentium 4 and I ended up spending much of the year 2001 rewriting my code for Pentium 4. Not a sustainable thing to do year after year. So you'd like to write code, even emulation code, in a higher level language and have the compiler tools do the tuning for you.
In addition to of course specifying the -O2 or -O3 optimization switch, with C and C++ compilers there are two options than be selected at compile time to statically optimize code:
- ask the compiler to produce generic (sometimes called "blended") x86 code that will run ok on all x86 processors, but likely not optimally on any of them, or
- ask the compiler to target a specific processor such as Pentium 4, at the expense of further killing performance (or even compatibility) with other processors.
Even 15 years ago when there wasn't as much diversity that was what Intel expected software developers to do; you had to favor one specific processor at best. Fast forward to 2015 and throw into the mix now AMD's Opteron and Jaguar processors, many new generations of Intel processors with varying instruction sets and characteristics, and of course the increasing spread of ARM devices with any number of instruction set variations and implementation differences. What is a software developer to do? Recompile 30 different versions of the same app for 30 different target platforms, and in many cases needing to use completely different compilers? That is insane! And yet building multiple binaries is exactly how many applications have been getting built for years (if even offering 32-bit and 64-bit variants of the same application for the same platform in the false belief that 64-bit is faster).
Let me show why even if you did such an insane thing and recompile your code for every possible chip out there, you code is rarely ever ideal, and even compiling for 64-bit is not the right answer. Native C/C++ compilers today still miss some stupid simple optimizations. Over the years I've accumulated a number of compiler stress tests and regression tests. It generally starts with me debugging some code one instruction at at time, spotting a silly code sequence, and then distilling down my source code to still produce the silly code sequence.
One of the areas where most compilers are weak is in the handling of 64-bit integer data types (long long, __int64, uint64_t). Traditionally 32-bit x86 compilers have always performed 64-bit arithmetic by breaking down the operations into two 32-bit operations on the upper 32 bits and lower 32 bits. This has led to be false belief that blindly recompiling code for 64-bit mode is the right solution, and ignores the fact that Intel processors have supported some 64-bit integer operations since the days of the 486 and Pentium (by using the x87 floating point stack) and the Pentium MMX, and have had full 64-bit arithmetic support since the days of SSE2 introduced in 2000. Yet today, 15 years later, most C/C++ compilers will not touch the MMX or SSE register file to perform 64-bit integer arithmetic, choosing instead to produce stupid inefficient 1980's 32-bit code sequences.
Much as 16-bit integers were too small to do useful work with and most code gravitated to 32-bit arithmetic, 32-bit integers are sometimes too small as well. A billionaire's net worth in pennies cannot be represented in a 32-bit integer, because 2^32 pennies would only represent about 42 million dollars. Even the 16 gigabytes of RAM in my laptop cannot be represented by a 32-bit integer. Even the clock speed of my CPU now exceeds 2^32 Hz, and as I found a few years ago all of my existing benchmark programs that I wrote using a 32-bit integer to hold the clock speed blew up. What I hit was an integer overflow, the "rolling over of the odometer" when trying to represent a value larger than 4294967295. And so I updated my code to use 64-bit integers, at the cost of knowing that the C compiler would emit stupid code when manipulating that integer.
32bit integer overflow is so common actually that it is one of the major attack vectors used by malware. Or an unintentional bug that puts people in mortal danger, as we saw in this week's news about Boeing 787 having a 32-bit integer overflow bug in the plane's software. Because if you measure time in 10 millisecond time intervals, and you store that interval as a 32-bit signed int32, when you overflow from 0x7FFFFFFF to 0x80000000 just 248 days later, bad things will happen unless you've rebooted the plane to reset the counter. Some of you may recall the similar Windows 95 GetTickCount() overflow that required Windows 95 machines to be rebooted every 49 days.
Let me show how terrible modern compilers still are at dealing with 64-bit integers and other optimizations that should be stupid simple to handle. Take this simple wrapper function that acts as a shim to check for a special case of one of the input arguments:
#include <stdint.h>
typedef int pfn(void *p, uint64_t *x);
int foo1(pfn p, uint64_t *x)
{
uint64_t y = ((uint64_t)p) + *x;
if (y == 0) return 0;
return (*p)((void *)p,x);
}
A pretty stripped down test case that should be no problem for a smart compiler like Clang 3.6 (http://clang.llvm.org/), Visual Studio 2015 (https://www.visualstudio.com/) or GCC (https://gcc.gnu.org/), right? I take two parameters passed in registers, check if they add up to zero and if so return early, otherwise pass them on untouched to the wrapped function. Here is the 64-bit compiled code generated by Visual C 2015 that I will use as reference to show that even 64-bit code is sub-optimal
; uint64_t y = ((uint64_t)p) + *x;
00000 4c 8b 02 mov r8, QWORD PTR [rdx]
00003 4c 8b c9 mov r9, rcx
00006 4c 03 c1 add r8, rcx
; if (y == 0) return 0;
00009 75 03 jne SHORT $LN2@foo2
0000b 33 c0 xor eax, eax
0000d c3 ret 0
$LN2@foo2:
; return (*p)((void *)p,x);
0000e 49 ff e1 rex_jmp r9
As per 64-bit Windows calling convention the two arguments are passed in RCX and RDX registers, and the return value is returned in RAX. The compiler uses the scratch registers R8 R9 to avoid spilling registers to the stack. And when calling the second function the compiler has used a "tail call" optimization to turn a CALL RET sequence into a single JMP. So far so good.
But the compiler misses two easy optimizations that I would have done if writing this in assembly code:
there is no need to copy the input argument in RCX to R9, just jump directly through RCX itself, and,
had the compiler used RAX as the scratch register instead of R8, the value of zero would have been computed in RAX and would avoid needing the XOR EAX,EAX instruction.
The more optimal code could look like this:
mov rax, QWORD PTR [rdx]
add rax, rcx
jne SHORT $LN2@foo2
ret 0
$LN2@foo2:
rex_jmp rcx
Five instructions instead of seven, but ok, let's call that "close enough" for now. Now let's look at the 32-bit output produced by 32-bit Visual C 2015, 32-bit Clang 3.6 for Windows, and 32-bit GCC 5.1, where each one was passed -O2 optimization flag and -arch:AVX2 or -march=core-avx2 flag to generate Haswell code, and told to use register calling convention:
; {
00000 56 push esi
00001 57 push edi
00002 8b f9 mov edi, ecx
; uint64_t y = ((uint64_t)p) + *x;
00004 33 c0 xor eax, eax
00006 8b f7 mov esi, edi
00008 03 32 add esi, DWORD PTR [edx]
0000a 13 42 04 adc eax, DWORD PTR [edx+4]
; if (y == 0) return 0;
0000d 0b f0 or esi, eax
0000f 75 05 jne SHORT $LN2@
00011 5f pop edi
00012 33 c0 xor eax, eax
00014 5e pop esi
; }
00015 c3 ret 0
$LN2@:
; return (*p)((void *)p,x);
00016 ff d7 call edi
00018 5f pop edi
00019 5e pop esi
; }
0001a c3 ret 0
The 32-bit version requires 17 instructions instead of 7, or 5. Because traditional 1980's 32-bit x86 lacks additional scratch registers, the compiler spills ESI and EDI (in place of the R8 and R9 that were available in 64-bit mode). The spill of EDI is required merely for the tail call, and had the compiler jumped through ECX the push and two pops of EDI would be unnecessary. Similarly, if the compiler reversed the order of arguments to the OR instruction to be OR EAX,ESI it would be able to optimize away the XOR EAX,EAX. So already 4 instructions that I could easily optimize away.
In fact it's worse, because whether the OR instruction is coded as OR ESI,EAX or OR EAX,ESI, if the output of an OR operation is zero, that means that both inputs are zero regardless, which means that EAX is zero anyway. So using traditional 1980's 32-bit x86 this could have been a 13 instruction sequence.
Let's look at the output of the latest Clang 3.6 clang-cl compiler for Windows (in Clang's slightly different assembly listing format):
@foo2@8:
# BB#0: # %entry
pushl %edi
pushl %esi
movl 4(%edx), %esi
movl (%edx), %edi
addl %ecx, %edi
adcl $0, %esi
xorl %eax, %eax
orl %edi, %esi
je LBB1_2
# BB#1: # %if.end
calll *%ecx
LBB1_2: # %return
popl %esi
popl %edi
retl
Clang does in fact generate 13 instructions, but misses the same trick with the OR instruction to avoid spilling one register. Had Clang used EAX in place of EDI, it would have eliminated 3 instructions (PUSH EDI, XOR EAX,EAX, POP EDI) and brought the instruction could down to 10. Close but no cigar.
Now let's look at how GCC 5.1 compiles this code on Linux using the gcc regparm attribute instead of __fastcall:
foo:
pushl %esi
movl %eax, %ecx
pushl %ebx
movl %eax, %ebx
subl $4, %esp
sarl $31, %ebx
addl (%edx), %ecx
adcl 4(%edx), %ebx
movl %ebx, %esi
orl %ecx, %esi
jne .L7
addl $4, %esp
xorl %eax, %eax
popl %ebx
popl %esi
ret
.L7:
call *%eax
addl $4, %esp
popl %ebx
popl %esi
ret
That is 21 instructions! As most people have come to realize, GCC is falling behind Clang both in terms of popularity and code quality and produces even worse code than Visual C 2015. None of these three compilers emitting anything beyond 80386 level x86 from 1986, which is a shame. Only Intel's latest ICC 15 compiler actually bothers to emit AVX2 code and make use of 64-bit integer operations available in AVX2:
movl %edx, %ecx
cltd
vmovd %eax, %xmm0
vmovq (%ecx), %xmm3
vmovq .L_2il0floatpacket.0, %xmm5
vmovd %edx, %xmm1
vpunpckldq %xmm1, %xmm0, %xmm2
vpaddq %xmm3, %xmm2, %xmm4
vpand %xmm5, %xmm4, %xmm6
vptest %xmm6, %xmm6
jne ..B1.3
xorl %eax, %eax
ret
movl %ecx, %edx
movl %eax, %ecx
jmp *%ecx
It is not the shortest sequence or the fastest, but Intel is on to something. Notice that Intel's code has no PUSH or POP instructions, no unnecessary 32-bit register spills, and instead uses available XMM scratch registers. The code sequence generated uses Haswell's AVX2 encodings for MOVD, MOVQ, PADDQ, etc. but drop the 'v' from the mnemonic and you would have perfectly valid SSE2 code that runs on any 32-bit processor since 2001. I would have written Intel's code slightly differently, I can handcode the AVX2 version of this function using just 6 instructions, so Intel has a long way to go too.
But I am pleased that Intel is exploring this. For the past 14 or 15 years, MMX and XMM register state have been all but ignored by 32-bit compilers, leaving most 32-bit applications compiled as 1980's or 1990's quality code.
I have to give kudos to Intel for their Intel Technical Webinar Series, a long running series of weekly streaming sessions every Tuesday morning at 9am Pacific which explore things like new features in Intel's C compiler, parallelism and threading, using VTune, and other tips and tricks that all software engineers should be interested in. They have years worth of archived webinars here: https://software.intel.com/en-us/articles/intel-software-tools-technical-webinar-series
Ok, so let's lob an easy one to the compiler, let's modify the addition operation in the test function to an OR operation, which should greatly simplify the code because there is no upper 32 bits of carry bits to propagate:
#include <stdint.h>
typedef int pfn(void *p, uint64_t *x);
int foo2(pfn p, uint64_t *x)
{
uint64_t y = ((uint64_t)p) | *x;
if (y == 0) return 0;
return (*p)((void *)p,x);
}
Unfortunately, this still doesn't help. Microsoft's compiler still doesn't tail merge, neither compiler uses EAX as a scratch register of the OR operation and still ends up spilling an unnecessary register. So now let's REALLY dumb it down:
int foo3(pfn p, uint64_t *x)
{
return (*p)((void *)p,x);
}
This is now just a simple pass-through wrapper function. The compiler only has to emit a JMP ECX instruction, that's it! Unfortunately, Visual C produces this:
mov eax, ecx
jmp eax
while Clang 3.6 produces this, no tail-call optimization:
calll *%ecx
retl
This is frustrating, that after almost 25 years of 32-bit x86 compilers simple code sequences like this still not being optimized. But, it's never too late to start optimizing your code better, and so if you still find yourself compiling with gcc 3.x or gcc 4.x, Visual Studio 2012 or earlier, it is time to upgrade your compiler.
Native compilers get serious upgrades
At the conclusion of my Haswell post two years ago I promised to follow up with what I called "happy new features" in Visual Studio 2013. The product was still a few months from shipping at that time, but now I can share and tell you about some features I can't do without any more. Here is my list of Visual Studio 2013 "don't leave home without them features":
Designated initializers in C
This is actually an old C99 language feature that sadly was lacking and long overdue in Visual Studio that finally appeared in Visual Studio 2013 Update 2 last year. It is the C syntax that permits initializing data structures by field name, as opposed to the implicit order of the fields. If you have ever tried to port over some open source code from Linux to Windows, for example the FFMPEG library, you know the problem. C99 permits initializing a structure in this manner to allow freedom in making changes to the structure order and layout without updating all the places where the structure is initialized. For example, in this snippet of FFMPEG code below, it is not relevant in what order the fields "name" and "type" are actually defined in the structure. This fix now also makes it easier to port other projects like LLVM, Clang, QEMU, and other popular packages. In fact, Clang requires VS2013 Update 2 in order to build now.
AVCodec ff_eightsvx_fib_decoder = {
.name = "8svx_fib",
.type = AVMEDIA_TYPE_AUDIO,
Vector calling convention - announced on MSDN two years ago (http://blogs.msdn.com/b/vcblog/archive/2013/07/12/introducing-vector-calling-convention.aspx) the __vectorcall keyword is an enhancement to the __fastcall calling convention in 32-bit x86 and to the default register calling convention in 64-bit x64. It permits passing vector types (__m128, __m128i, __m256d...) in XMM and YMM vector registers, as opposed to the old behavior of putting the data on the stack and passing by reference as is done with large structures. In effect, it gives you more registers to pass arguments in if you package your data appropriately.
/analyze - I don't know how I ever did without this feature, but /analyze has proven to be invaluable in tracking down bloat and subtle bugs in my code. The /analyze switch instructs the compiler to do more thorough static analysis on your code, looking for things such as potential null pointer dereferences. Existing in previous versions of Visual Studio, the 2013 version was enhanced to support an option /analyze:stacksize which flags any functions whose local frame size exceed some value. I typically specify /analyze:stacksize1024 in my Release builds to tell the compiler to flag any functions that exceed 1K of stack space, as this is generally indicative of large arrays or other bloat that perhaps should be looked at. In my case I find this tends to find debug-only code that I forgot to #ifdef appropriately.
AVX2 support - appearing just recently in the Visual Studio 2013 Update 4 release a few months ago, the -arch:AVX2 switch was added to specifically emit Haswell AVX2 and BMI instruction extensions. If you are developing code that you know targets Haswell devices such as a Surface Pro 3 or the AWS C4 instance type, throw the switch. Otherwise, use the default -arch:SSE2 switch (which is actually the default in VS2013). Should you really need to emit 1990's compatible 32-bit code, the new switch -arch:IA32 does that.
Another great reason to upgrade to Visual Studio 2013 is because it is free. The Visual Studio 2013 Community Edition is available from https://www.visualstudio.com/ for personal use and use by small teams. Same optimizing compiler with the features I listed at no cost (which I will argue is long overdue on Microsoft's part given that Linux comes with gcc and clang for free and Mac OS X comes bundled with Xcode). It is great to see the new CEO, a former developer himself, finally supporting developers, developers, developers.
.NET Native for Windows 10
Moving on to the Visual Studio 2015 Release Candidate just posted a few days ago, several more cool new features have been added. The first one is a new C# compiler called .NET Native (https://msdn.microsoft.com/en-us/vstudio/dotnetnative) which ingests MSIL bytecode and emits native Intel code. This is similar to the old NGEN compiler which invoked the .NET JIT compiler offline to perform an ahead-of-time (AOT) precompilation of .NET code to native code. The difference is that .NET Native produces a true self-contained native Windows executable that can be run directly without any need to install the .NET Framework. And it goes through the same C2.DLL optimizing compiler back end code generator as C and C++, producing code that is almost as fast and optimal as native C/C++ code.
Control Flow Guard
A new feature in VS2015 called Control Flow Guard is activated by the compiler switch /guard:cf. http://blogs.msdn.com/b/vcblog/archive/2014/12/08/visual-studio-2015-preview-work-in-progress-security-feature.aspx
This feature performs control flow checks when dereferencing indirect function pointers, and halts your program if a tampered function pointer is detected. This is similar to the checks that Google's Native Client performs to prevent an escape from the sandbox, and similar to the existing -fsanitize=cfi options in Clang. The latest updates to Windows 8.1, as well as the Windows 10 preview builds, are built with this support already.
Speaking of Clang (http://clang.llvm.org/), I've been very impressed by this open source compiler, which is really a combination of the Clang C/C++ front end and the LLVM code generator as the back end. Clang grew in popularity as an alternative to GCC, which in recent versions has been poisoned by the GPL3 license. The more sane licensing terms of Clang and LLVM have attracted the likes of Apple, Google, Microsoft, and Oracle to support Clang in various ways.
Link-time optimizations
The LTCG (link-time code generation) functionality feature has existed in Visual Studio for about 10 years, and is a must-have compiler switch that I always use now for building my Windows apps. One drawback of LTCG in Visual Studio 2013 and earlier is that because code generation is deferred until link time, even a one-line edit to one source file required recompiling the entire project. For something like the latest Bochs 2.6.8 release which requires compiling and linking over 270 individual modules, the link stage can take anywhere from about 18 seconds on my Haswell desktop machine to as much as a minute on my Core 2 machine. Visual Studio 2015 now adds a -LTCG:INCREMENTAL linker switch which is smart enough to only recompile modules that are directly affected by the edit made. So for example if I merely update a line of code in one function, the linker now only invokes LTCG on that one function and re-evaluates its inlining decisions on callers and callees of that function. If the edit is small enough then no further compilation propagates, and in the case of Bochs 2.6.8 I've found the LTCG link time for minor edits drops from 18 seconds down to 3 seconds!
Recent versions of GCC 4.9 and 5.1 as well as Clang now support decent implementations of LTCG that they call LTO (link time optimization) which is enabled with the -flto compiler switch. What LTCG/LTO perform are automatic features that used to have to hand tuned by the programmer - which functions to inline and which to not, when to use register calling convention, separating out cold code from the mainline path of a function, etc. In my experience, whenever I use LTCG/LTO to build Bochs or other performance critical applications and combine that further with PGO (profile guided optimization) that feeds execution data back into the link process, I get a 10% to 30% speedup. Earlier releases of GCC prior to 4.9 tended to blow up when using -flto (due to running out of memory at compile time or other asserts due to compiling everything at once at link time) but now appears to be is usable. I find that using -flto even benefits something like the build of QEMU itself, for although QEMU is thought of as a binary translator that generates code on-the-fly, QEMU is full of statically compiled C helper functions that do in fact benefit from link-time optimization.
Android Run Time
.NET Native is not the only ahead-of-time compiler for managed languages. Last year for the release of Android 5.0 Lollipop, Google replaced the default Dalvik Java VM with a new runtime called ART (Android Run Time, https://source.android.com/devices/tech/dalvik/index.html) which similarly pre-compiles Java apps to native code. In fact just announced this week, Google is prepping an even more optimal version for Android 6.0 (http://www.tomshardware.com/news/android-runtime-art-optimizing-compiler,29035.html).
I've not experimented with ART yet or the Java pre-compilation, but it raises interesting possibilities. Java based emulators, such as the excellent JPC (https://github.com/ianopolous/JPC) potentially stand to benefit from having more advanced compiler optimizations applied than a simple JIT can provide. JPC is pretty cool, it's an x86 emulator like Bochs, it's a debugger, but under standard Java is a bit slow due to all the virtual method calls, four of them per emulated x86 opcode.
There is another benefit to pre-compiling Java application code which is it can avoid the double-jit problem should the system itself be running under an emulated virtual machine.
Objective C in Visual Studio 2015
That's right, even Microsoft now supports Clang as the compiler for their newly announced Objective C support in Visual Studio 2015 disclosed last week at BUILD: https://channel9.msdn.com/events/Build/2015/3-610
When I saw that last week, my brain exploded just a tiny little bit. The new CEO really gets it. A single tool chain in Visual Studio 2015 that supports writing in any of the C family of languages to create standalone native Windows 10 .EXE files.
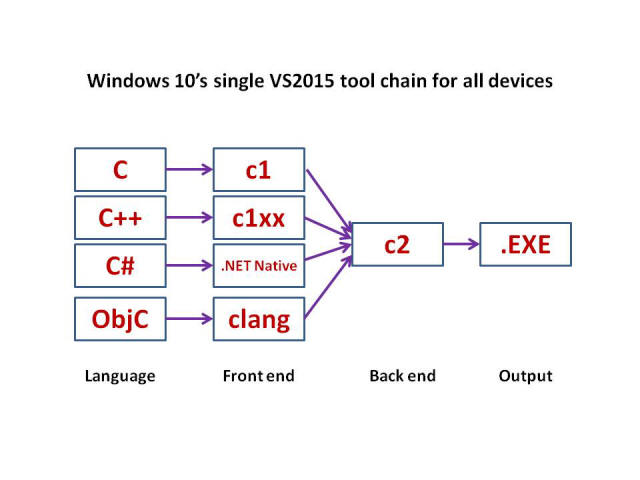
As was mentioned at one of the Q&A sessions at BUILD last week, Microsoft wants their tools to build "every dude's 'for' loop", including for Mac OS X, Android, and Linux (http://openness.microsoft.com/blog/2015/04/30/build-2015-windows-ios-android-mac-linux-developers/). That blows my mind. Not since the early and mid-1990's when I worked in the Macintosh Business Unit at Microsoft has Microsoft developed cross-compilers for the Mac.
Going beyond static compilation
In summary, static compilers still produce some silly code, but just the improvements in code quality over the past 12 months are quite amazing. If you are not using the latest versions of Visual Studio 2015, Clang 3.6, or GCC 5.1, you are throwing away performance. And the reason both Google and Microsoft are investing so heavily into AOT compilation to replace JIT is of course, code quality. As the world moves toward increasingly more battery powered devices, it is more efficient to do the heavy lifting of compiling complex Java or MSIL bytecode to native, once, at application install time as opposed to each time the app is run. So it is a good thing that these major compiler upgrades are showing up, better late than never. Clang's popularity is growing life wildfire, giving GCC a serious kick in the butt and bring a common compiler to platforms like Mac OS X, Android, Windows, and Linux.
This a good thing, this is why 2015 is not like the 1980's or 1990's. Today we have unified cross-platform toolsets that just did not exist back in the days of Apple Macintosh and Commodore 64 and IBM PC. When I attended the CGO 2015 conference a few months ago by far the most well attended standing room only workshop was the 8-hour long tutorial on LLVM, which was presented by Google. I guess now I can learn to write an LLVM optimization pass and fix these silly code generation issue myself! A good book for getting up to speed on building LLVM which I just began reading is Getting Started with LLVM Core Libraries (http://www.amazon.com/Getting-Started-LLVM-Core-Libraries/dp/1782166920/).

But what to do about all of the 20+ years of legacy code already out there that hasn't been compiled with the latest compilers? I will discuss that, CGO 2015, and a lot more when I complete this trilogy of posts with a dive in to dynamic compiler optimizations in Part 39.