NO EXECUTE!
(c) 2015 by Darek Mihocka, founder, Emulators.com.
May the 4th (be with you) 2015
Episode 20150504: It's Time To Get Serious About Code Quality

Happy Star Wars Day 2015. I knew the above picture would come in handy some day, I took that shot recently while visiting Bluff, New Zealand, one of the most southernmost towns in the south island, as it reminded me of the forest moon Endor. I have Star Wars on the brain this year since it is just a few more months until the next Star Wars movie is released, 10 years since the last batch of Star Wars movies.
Technology is like that as well, every 5 or 10 years something comes along that is a major seismic shift for good or bad. 1980's brought the home computer into our living rooms. 1990's was the decade of the 50% clock speed and performance increase per year and the "free lunch" of ever faster performance. 2000 brought us the Pentium 4 processor that not only brought clock speed increases to a crashing halt, but also spurred both software and hardware companies to do work to get more performance out of each clock cycle through efficiencies other than the free lunch of increasing clock speeds. Pentium 4 was unfortunately the Phantom Menace of the last decade. :-(
As anyone who had a Pentium 4 or read my blogs on the Pentium 4 knows the typical desktop PC, notebook, tablet or even cell phone is far more powerful and power efficient than the Pentium 4 of a decade ago despite the lack of clock speed increase. How can this be? This feat was accomplished by increasing parallelism in code, reducing code size, and reducing instruction counts. Over the past 10 to 12 years this has manifested itself by means of these hardware improvements in mainstream CPUs:
- ILP (Instruction Level Parallelism) is now exploited by out-of-order CPU pipelines such as the Haswell to execute up to 4 micro-ops per clock cycle (roughly equivalent to 4 x86 instructions, plus or minus) as the pipeline finds mutually exclusive instructions that can be computed in parallel. As I personally measured over the years, the Pentium 4's IPC (Instructions Per Cycle) rate - the average rate at which instructions are execute measured as instruction/cycles - was a pathetic 0.5 on most real-world Windows code that I measured. Core 2 and Opteron brought that up to about 1.0 or 1.1, and since then the various generations of Core i7 release have increased IPC to 1.3 then 1.5 and now even slightly higher thanks to wider and wider pipelines.
- SIMD (Single Instruction Multiple Data operations a.k.a. MMX, SSE, AVX) are instructions that can operate on multiple integer or floating point values at once using the same operations. For example, loading and storing up to 32 bytes per clock cycle as Haswell is capable of to improve memory copy speeds, or adding or subtracting multiple array elements as used by video compression,
- SMP (Symmetric Multi-core Processors), which take the power envelope of say 100 watts that might have been wasted on one very fast core and split it into two or four or more cores that each operate at a reduced clock speed. Since power consumption of silicon is proportional to more than the square of frequency (it is roughly between freq^2 and freq^3), a modest 20% reduction in clock speed can reduce the power consumption by 50%. Thus why from 2005 to 2006, Intel processors went from single-core 3+ GHz Pentium 4 chips to 2+ GHz Core 2 dual-core chips.
- Die shrinks, thanks to Moore's Law, have allowed chip makers to roughly halve the linear transistor size every 4 years, or halve the area every two years. Which is why every 2 years the silicon process (the measure of transistor size in nanometers) drops by a square root of 2 every two years: 90nm in 2004 (Pentium 4), 65nm in 2006 (Core 2), 45nm in 2008 (Core i7), 32nm in 2011 (Core i7 "Sandy Bridge"), 22nm in 2013 (Core i7 "Haswell"), and now in 2015 recent release of Haswell's die shrink - the 14nm Core i7 "Broadwell".
- Eliminating pipeline hazards - both AMD and Intel have been very good recently at eliminating or working around hazards, also known as pipeline bubbles or glass jaws. This occurs when an instruction causes a memory miss, a branch misprediction, or has a data dependency on a previous instruction that is not available yet. Even simple shift or addition operations can cause these as I've documented in the past. Pentium 4 was notorious for this, and even Core 2 was littered with them. For example, a register shift followed by a conditional branch introduced a hazard of over 10 clock cycles due to a partial register stall on the EFLAGS status register (this was corrected in Sandy Bridge in 2011, and on Core 2 required inserting a TEST instruction to set all flags without penalty). A misaligned memory access used to be very costly, but now other than some rare pathological cases misaligned accesses are usually free. And branch prediction, flow control used to regularly cause pipeline stalls due to mispredicted target addresses, which then causes the whole pipeline to stall and refetch code from the correct target.
- New instruction encodings - when the 8086 first came out that its instruction set for not that different from say 6502 or Z-80. All these instruction sets used an 8-bit opcode to encode an operation, followed by optional operand bytes to encoding things like memory addresses or constants. The philosophy was such that frequent operations were encoded in the fewest bytes, so for example common push and pop operations, function returns, incrementing/decrementing of registers were one-byte instructions. Unfortunately x86 has constantly been evolving for over 30 years, always adding and adding new instructions, which then necessitated using 2-byte opcodes, then three-byte opcodes, and ever larger instructions. Recent SSE4 instructions are typically 6 or more bytes in length, due to both large opcodes and numerous prefix bytes that modify an opcode. Decoding prefixes and just plain figuring out where in a sequence of code bytes the opcode itself is hiding is complex, which leads to larger and larger x86 decoder circuits in silicon which limit how many instructions can be decoded per clock cycle. Having a CPU pipeline that can execute 4 instruction per clock cycle is all fine and well, provided that you can fetch and decode 4 instructions per clock cycle. But up until Haswell, most Intel CPUs chocked when 2 or more prefix bytes were present, literally chocking off the front end of the CPU pipeline and lowering the IPC rate. AMD and Intel jointly solved this in 2011 with the release of the AVX (Advanced Vector Extensions) instructions, which replace legacy opcodes like 0x66 0xF3 0xF2 with new fixed-size "VEX" prefixes, which make the location of the actual opcode byte easier to locate by the decoder hardware. With next year's "EVEX" prefix debuting in Intel's Skylake architecture, up to 32 registers can be accessed instead of the usual 8 or 16. But Skylake is a discussion for next year ;-)
Together, these hardware improvements have vastly sped up the performance of legacy Linux and Windows code since the early 2000's without increasing clock speeds. It should really be no surprise that I was bouncing up and down with ecstasy back in 2013 when I made my posting about Haswell's Great Leap Forward. Think about it, the average laptop in the early 2000's ran at about 2 GHz and desktops were in the 3 GHz range. Today, well, my Surface Pro 2 tablet runs at 2.3 GHz and my desktop Core i7 peaks at 4 GHz. Yet compare the performance of applications today compared to back then and it's typically anywhere from a 3x to over 10x improvement on exactly that same code without any changes or recompilation. And code that does get recompiled and rewritten to take advantage of threading and SIMD can see improvement of 50x or more.
64-bit mode was a red herring
The features that Intel packed into the Haswell (and now Broadwell) generation I claim is cumulatively more powerful than even the introduction of 64-bit mode a decade ago, or the incremental SSE improvements that trickled out a decade ago. 64-bit mode I'll argue was even a bit of a distraction, because other than offering the 64-bit addressing useful to things like in-memory databases and OS kernels, there is virtually nothing that 64-bit extensions offer to user-mode applications that Haswell's features don't offer to 32-bit code. Most people forget that even 32-bit x86 processors in the late 1990's supported 64-bit integer operations, loads, stores, and register files (in the form of x87 integer load/store, MMX operations, and then later a robust set of 64-bit integer operations in SSE2). AMD adding 64-bit extensions in 2003's Opteron was more a marketing stunt than performance win. There is ample evidence for example that an "ILP32" (a.k.a. "x32") compilation model that uses 64-bit integers but retains 32-bit pointers and 32-bit addressing is actually faster than true 64-bit mode, something that I have personally verified in my own code, and as is documented on the x32 page https://sites.google.com/site/x32abi/. So a 32-bit program that is compiled to take advantage of Haswell's AVX2 instructions could likely outperform a "true 64-bit" build of the same program (due to reduced memory footprint and lower L1 data cache pressure).
Let me give you an example of a hardware improvement that is much more useful to performance than 64-bit mode...
"Hardware guys got it right"
Haswell has one more impressive trick, it has a vastly improved branch predictor compared to past Intel x86 processors, or for that matter, anyone else's x86 processors. I analyzed Haswell on my own code back in the summer of 2013, finding significant performance improvement on emulation code over Core 2 and Sandy Bridge, and now others have confirmed the same and identified why.
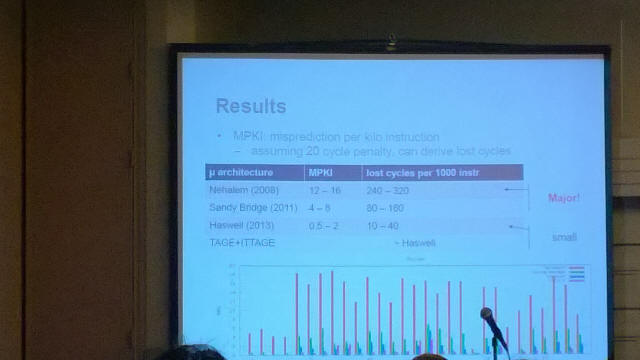
This past February I was attending the annual CGO (Code Generation and Optimization) conference in San Francisco and attended a talk entitled "Branch Prediction and the Performance of Interpreters - Don't Trust Folklore" (see https://hal.inria.fr/hal-00911146/ or https://hal.inria.fr/file/index/docid/911146/filename/RR-8405.pdf). In summary, these researchers looked at various interpreted-only virtual machines such as Python and measured the MPKI rate (Mispredictions Per Kilo Instructions, i.e. number of mispredicted branches per 1000 native x86 instructions during the execution of the interpreter). On early Core i7 hardware such as Nehalem, this mispredict rate, the MPKI, was found to be about in the 10 to 20 range. In other words, about 1% to 2% of instruction executed were a mispredicted branch, which as we know can cost as much as 25 cycles, and thus in effect add hundreds of cycles of stall per 1000 instructions. Sandy Bridge (the 2nd generation Core i7 from 2011) lowers that rate to single digits. Haswell lowers the MPKI rate to about 2 or less, equivalent to at most a few dozen cycles of stall per 1000 instructions, and an order of magnitude reduction in just a few years. In fact, using a model of an ideal branch predictor, they determined that Haswell was practically as good. As the presenter put it on that last slide - "Hardware guys got it right". (pardon my poor cell phone photos from the talk)


If you recall back in 2008 I made this post about my own research on predicting interpreters and found that even on Core 2 it was possible to write an interpreter that could dispatch an emulated instruction ever 6 clock cycles, leading to an interpretation rate of about 500 million guest instructions per second. On Nehalem today, that ideal overhead is still about the same, due in part to the fact that a predicted branch or jump still has a latency of 2 clock cycles, and any type of cache-hit memory operation to say, fetch the next opcode, has a latency of 4 clock cycles.
But the beauty of Haswell is that the near-perfect branch predictor ensures that the jump overhead will generally tend to be the 2 cycles and not 25 cycles. Bochs and other interpreters today routinely dispatch instructions in 15 cycles or less, indicating that on average most of the interpreted instructions dispatches are correctly branch predicted, and thus the "interpreter loop overhead" is bounded to about 6 clock cycles per interpreted instruction. (No wonder the Bochs x86 interpreter keeps nipping at the heels of the QEMU x86 jitter - interpretation has ever lower and lower overhead)
What the authors of this paper conclude is that the "big switch statement" dispatch portion of an interpret is no longer a performance bottleneck and for people to stop trying to hand optimize such loops in assembly or use other tricks like Duff's Devices. Instead, write a readable interpreter that is easy to maintain and let the hardware worry about the branch prediction.
Broadwell
This one-time quantum jump in performance that Haswell delivered is not an excuse for us software guys to slack off (like in the 1990's). This is not a Moore's law type of free lunch that will repeat itself next year. So even if the Python intepreter MPKI rate was to drop in half to below 1.0 next year that would be relatively insignificant to further improving interpreter performance.
The new die shrink of Haswell, released early this year as the Intel Broadwell processor pulls a few neat tricks, but otherwise I find at best it delivers about an average 4% IPC speedup over Haswell. Among Broadwell's interesting improvements that I've discovered:
- floating point multiply operations such as scalar MULSS and MULSD as well as their vector counterparts drop in latency from 5 clock cycles to 3 cycles. That means that floating point multiply now has the same 3-cycle latency as integer multiply. That's actually a pretty amazing advance, since it stands to benefit Linpack, N-body, and other floating point intensive benchmarks.
- the latency of AVX zeroing instruction VZEROALL appears to drop from 17 cycles to 13 cycles.
- long overdue, the partial EFLAGS hazard of INC DEC ADC SBB instructions finally appears to have been eliminated. These instructions were a huge thorn in the side of the Pentium 4 and even Core 2. Sandy Bridge brought these down to just 1 extra cycle of latency, and now Broadwell appears to have completely eliminated the overhead. This is actually significant for "branch-free" code that uses carry flag tricks to create masks and do value selection.
- further branch prediction improvement - normally CALL and RET instructions are perfectly matched and so the hardware uses a shadow stack to cache and branch predict target addresses of a RET instruction. Old gcc code that uses CALL to the next instruction to figure out the current program counter has the side effect of misaligning this hardware RAS (return address stack) and causing subsequent RET instructions to mispredict. Broadwell appears to cut this penalty in half.
Some cool tricks, but impacting the long tail of glass jaws and hazards, and thus only about a 4% speedup on real world code. The real benefit of Broadwell is the lower power consumption over Haswell, and correspondingly thinner smaller devices that it can be put into. In March I bought the new generation of Intel NUC (Next Unit of Computing) based on Broadwell (http://www.amazon.com/gp/product/B00SD9ISIQ/). Much like last year's NUC it measures about 4 inches by 4 inches, but is now slightly thinner and can drive (as I've verified) two 4096x2160 4k displays at once, a very nice 16-megapixel dual-monitor setup. As many times as I have worked on a computer, it does amaze me how small and fast these things are getting:


No more free lunch - Now it is software's turn to step up and deliver improvements
Reducing branch misprediction rates and eliminating glass jaws is terrific progress in hardware. Compared to Intel processors from just 5 or 6 years ago there is easily a 50% or more performance gain to be had by just upgrading processors and doing nothing else. Your old legacy code will run that much faster, meaning that (and I have verified this with side-by-side benchmarks), that $400 Intel NUC box picture above beats the pants off my $3000 Intel Xeon based Mac Pro that's as heavy as a block of concrete. But there is so much more low hanging fruit to be had. It is a matter now of people like me (and likely you the reader) - software developers - to make the effort to take advantage of those new Haswell/Broadwell features.
Code quality matters. In the old days of fixed frequency machines like Apple II, Atari 800, Commodore Amiga, once your code ran well enough you shipped it. That's because in those days the devices were plugged in to AC power and the customer paid for electricity. Today in the age of cloud computing where you the software provider are footing the bill for every clock cycle that your hosted software consumes, code quality matters a lot. Same with the other end of the spectrum with battery powered devices, saving clock cycles means extending battery life. In this modern age there is no such thing as "fast enough", it always benefits you to make your software even more efficient.
For example, while working at Amazon Web Services in 2014 I had the pleasure of beta testing the Haswell Xeon based "C4" instance type (described here: https://aws.amazon.com/blogs/aws/new-c4-instances/). As expected as I migrated instances from older hardware platforms to Haswell the performance shot up measurably, despite the pricing of C4 being similar to that of earlier instance types like C3 and CC2 (thus delivering a higher "bang for the buck" than before). That's the "free lunch" portion, maybe Haswell's ILP improvements give you a 30% or 50% one-time speedup. But that's cheating, and unfair to you and the users of your software, because by not taking explicit advantage of new features like AVX2 and multi-core you could be leaving another 2x or even 10x performance gain laying on the table.
And this is not just specific to Haswell. As I mentioned last time, ARM is also making great strides, from the clock speed improvements the past few years that now top 2 GHz, to 64-bit extensions and SIMD extensions, to the availability of all sorts of powerful inexpensive hobby machines such as the Google Chromebook than can run both Chrome OS and ARM versions of Linux, the nVidia Jetson board that runs an ARM-based version of Ubuntu 14.04 and outputs 4K video right out of the box for less than $200, the Raspberry Pi, and other boards. Yes, ARM (and Atom) are mostly low-power in-order cores that deliver between 1/2 and 1/4 the IPC rate than a "big core" like Haswell does, but it's not less reason to ignore code quality. Code compiled for ARM two or three years ago is already out of date and sub-optimal.
Before you jump to conclusions, I am not steering you toward writing in assembly language, quite the contrary! Over the years as I've learned to tease out performance tricks out of not only Intel processors but PowerPC and ARM I had for years convinced myself that performance meant needing to write the code in assembly language. As I described in my previous post in 2013, I was experimenting with various ARM devices such as the Microsoft Surface and the Chomebook and was impressed at how mature the toolsets were for those devices, and thus could skip the hassle of writing thousands of lines of new ARM code. Instead, I rewrote the few thousand lines of very Intel-specific x86 assembly code that was my 6502 interpreter code in Gemulator 9.0 (sources here) and converted the file x6502.asm to a C-based interpreter x6502.c. The performance of the compiled C code on the Tegra 3 ARM processor in the Surface RT was about the same or even faster (taking into account adjusting for clock speed) as that same code compiled for x86 running on Intel Atom. My port from x86 assembly to C code resulted in barely any performance difference from my x86 assembly code that I wrote over 20 years ago! I learned a similar lesson back in 2008 trying to optimize the Bochs x86 interpreter and seeing that it was less about assembly vs. C as it was about minimizing CPU pipeline hazard, such as branch mispredictions. Whether you write an "if / else" in Java, C++, or code up a CMP / JNE in assembly, a mispredicted branch costs the same 20 to 25 clock cycles in all those cases, assembly code is no more superior than Java or C++ in that respect.
This conclusion that C or C++ can be as fast as assembly code would not have been true 15 or 20 years ago. The quality of C/C++ compilers has vastly improved in the past decade thanks to things like register calling conventions becoming commonplace, profile guided optimization becoming a first-class citizen in both gcc and Visual C/C++, and just plain better global optimizers in the compile back ends. Just in the past couple of years there has been incredible progress in compilers as I will elaborate on in my next post. If you shipped any code more than two years ago you will want to take a look at these new ways to make your code faster.
IoT
Internet of Things - a broad term that implies a world full of different sized devices running different hardware - in this decade that means MP3 players, computers that we wear on our wrists, cloud computing servers in data centers, apps pre-loaded onto a television, drones and other wireless toys, Android and Windows tablets, laptops, and of course good old desktop computers. Devices span not only a range of CPU architectures, but also a wide range of clock speeds and memory sizes (in some cases LOWER clock speeds and LOWER memory sizes than we've gotten used to) which only further necessitates the need to heavily focus on code quality. "It runs on my development machine, so ship it!" is no longer a valid software release criteria.
An explosion of IoT devices could end up blowing up and fragmenting the industry much like happened after the 1980's. Apple, Atari, Commodore, IBM, Kaypro, Sinclair, Tandy, Wang, and others offered a wide range of devices all running different operating systems, different languages, different CPUs, and different applications. Hardly anything interoperated, i.e. my Atari 800 couldn't play Apple II games, a Wang PC wasn't quite compatible with an IBM PC, Apple Macintosh didn't run Apple II games, even Commodore 64 and Commodore VIC-20 weren't compatible despite being on the market at the same time from the same company. The end result is certain hardware/software platforms won (the PC, the Mac) while most others (including my dear Atari Computers) died due to having too small a market share, too few apps, or even inadequate developer tools (think PS/3 and all the wasted hype about the Emotion Engine). Remember, the whole reason that drew me into emulation back in 1986 and since develop interpreters and binary translators and virtual machines was to solve the interoperability issue of running Apple II games on my newer 32-bit computers. Emulation was a brute force solution to a problem that did not necessarily have to exist in the first place. So is there some way to avoid repeating this same market fragmentation today?
There is another
The answer is yes! 2015 is not 1980, and the world is quite different in terms of collaboration, open source projects, open source silicon, and the much richer set of development tools and languages that exist today. We're not developing in isolation anymore, we're not hacking assembly code touching the bare metal hardware anymore. There is another alternative - in fact there are many other alternatives - that could allow us to write optimal code for not just Haswell but also ARM and other processors.
In the next two more technically oriented posts later this week (this is a trilogy after all!) I will take a look at some of these new technologies and give an overview of what I saw at CGO 2015 (http://cgo.org/cgo2015/) and other events including last week's stunning Microsoft BUILD conference (https://channel9.msdn.com/events/build/2015?wt.mc_id=build_hp).
A quick heads up, Bochs 2.6.8 was released yesterday, with support for emulating Broadwell and Skylake's future AVX-512 instructions, download it here: http://bochs.sourceforge.net/
The QEMU emulator was updated last week, now also with support for emulating Broadwell, download QEMU release 2.3 here: http://wiki.qemu.org/Download
VirtualBox 5.0 is in beta, now with support for virtualizing AVX instructions and YMM state, download it here: https://www.virtualbox.org/
If you have any questions or comments, please email me directly at: darek@emulators.com
Continue now to part 38